



Supervised Learning with scikit-learn - Part 2
Chapter 2 - Regression
In this chapter, you will be introduced to regression, and build models to predict sales values using a dataset on advertising expenditure. You will learn about the mechanics of linear regression and common performance metrics such as R-squared and root mean squared error. You will perform k-fold cross-validation, and apply regularization to regression models to reduce the risk of overfitting.
import pandas as pd
import numpy as np
import warnings
pd.set_option('display.expand_frame_repr', False)
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
Predicting blood glucose levels:
df = pd.read_csv('./datasets/diabetes_clean.csv', index_col=None)
df.head()
Creating feature and target arrays:
diabetes_df = df.loc[(df['glucose'] != 0) & (df['bmi'] != 0)].copy()
X = diabetes_df.drop("glucose", axis=1).values
y = diabetes_df["glucose"].values
print(type(X), type(y))
display(X[:5,:])
Making predictions from a single feature:
X_bmi = X[:,4]
print(X_bmi[:5])
print(y.shape, X_bmi.shape) # confirm its shape
# sklearn use 2D data, so we reshape it
X_bmi = X_bmi.reshape(-1, 1)
print(X_bmi.shape)
Plotting glucose vs. body mass index:
import matplotlib.pyplot as plt
plt.scatter(X_bmi, y)
plt.ylabel("Blood Gluecose (mg/dl)")
plt.xlabel("Body Mass Index")
plt.show()

Fitting a regression model
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_bmi, y)
predictions = reg.predict(X_bmi)
plt.scatter(X_bmi,y)
plt.plot(X_bmi, predictions, color='black')
plt.ylabel("Blood Glucose (mg/dl)")
plt.xlabel("Body Mass Index")
plt.show()

Creating features
In this chapter, you will work with a dataset called sales_df, which contains information on advertising campaign expenditure across different media types, and the number of dollars generated in sales for the respective campaign. The dataset has been preloaded for you. Here are the first two rows:
| tv | radio | social_media | sales | |
|---|---|---|---|---|
| 1 | 13000.0 | 9237.76 | 2409.57 | 46677.90 |
| 2 | 41000.0 | 15886.45 | 2913.41 | 150177.83 |
You will use the advertising expenditure as features to predict sales values, initially working with the "radio" column. However, before you make any predictions you will need to create the feature and target arrays, reshaping them to the correct format for scikit-learn.
Instructions:
- Create X, an array of the values from the sales_df DataFrame's "radio" column.
- Create y, an array of the values from the sales_df DataFrame's "sales" column.
- Reshape X into a two-dimensional NumPy array.
- Print the shape of X and y.
sales_df = pd.read_csv('./datasets/advertising_and_sales_clean.csv', index_col=None)
sales_df.head()
import numpy as np
# Create X from the radio column's values (.values to make sure they are numpy array)
X = sales_df['radio'].values
# Create y from the sales column's values
y = sales_df['sales'].values
# Reshape X
X = X.reshape(-1,1)
# Check the shape of the features and targets
print(X.shape, y.shape)
Building a linear regression model
Now you have created your feature and target arrays, you will train a linear regression model on all feature and target values.
As the goal is to assess the relationship between the feature and target values there is no need to split the data into training and test sets.
X and y have been preloaded for you as follows:
python:
y = sales_df["sales"].values
X = sales_df["radio"].values.reshape(-1, 1)Instructions:
- Import LinearRegression.
- Instantiate a linear regression model.
- Predict sales values using X, storing as predictions.
from sklearn.linear_model import LinearRegression
# Create the model
reg = LinearRegression()
# Fit the model to the data
reg.fit(X,y)
# Make predictions
predictions = reg.predict(X)
print(predictions[:5])
See how sales values for the first five predictions range from $95,000 to over $290,000. Let's visualize the model's fit.
Visualizing a linear regression model
Now you have built your linear regression model and trained it using all available observations, you can visualize how well the model fits the data. This allows you to interpret the relationship between radio advertising expenditure and sales values.
The variables X, an array of radio values, y, an array of sales values, and predictions, an array of the model's predicted values for y given X, have all been preloaded for you from the previous exercise.
Instructions:
- Import matplotlib.pyplot as plt.
- Create a scatter plot visualizing y against X, with observations in blue.
- Draw a red line plot displaying the predictions against X.
- Display the plot.
import matplotlib.pyplot as plt
plt.figure(figsize=(8,6))
# Create scatter plot
plt.scatter(X, y, color="blue")
# Create line plot
plt.plot(X, predictions, color="red")
plt.xlabel("Radio Expenditure ($)")
plt.ylabel("Sales ($)")
# Display the plot
plt.show()

The model nicely captures a near-perfect linear correlation between radio advertising expenditure and sales! Now let's take a look at what is going on under the hood to calculate this relationship.

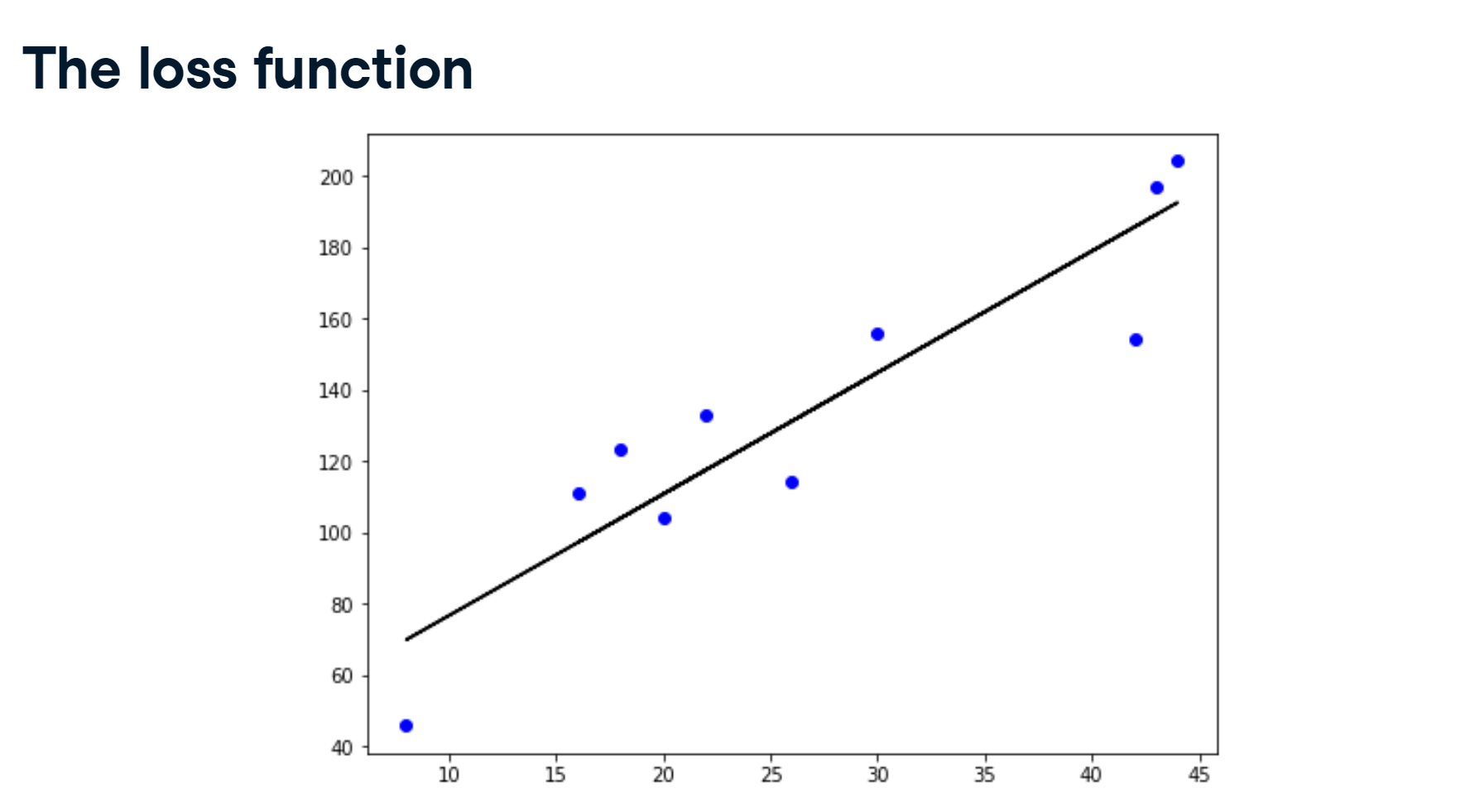
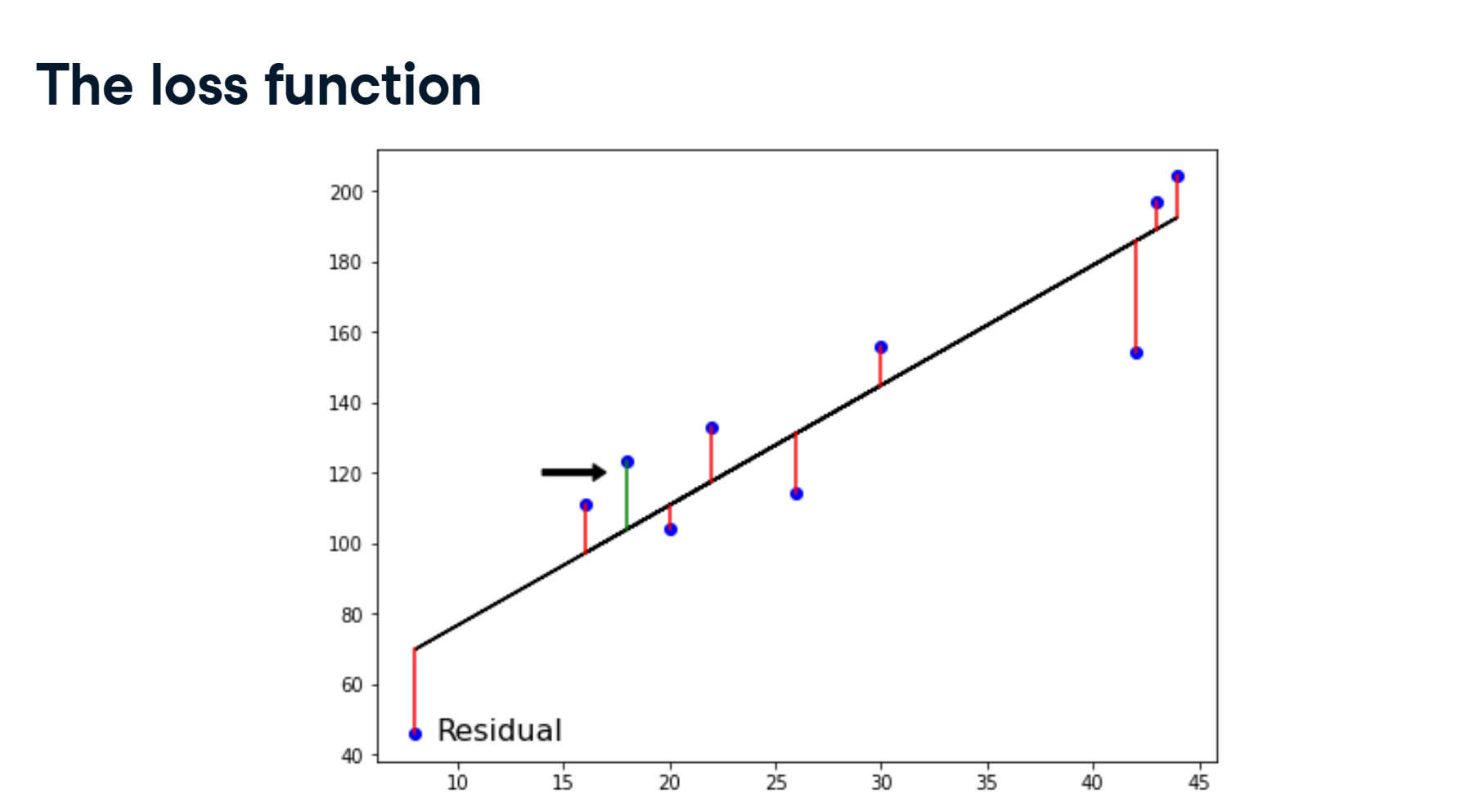
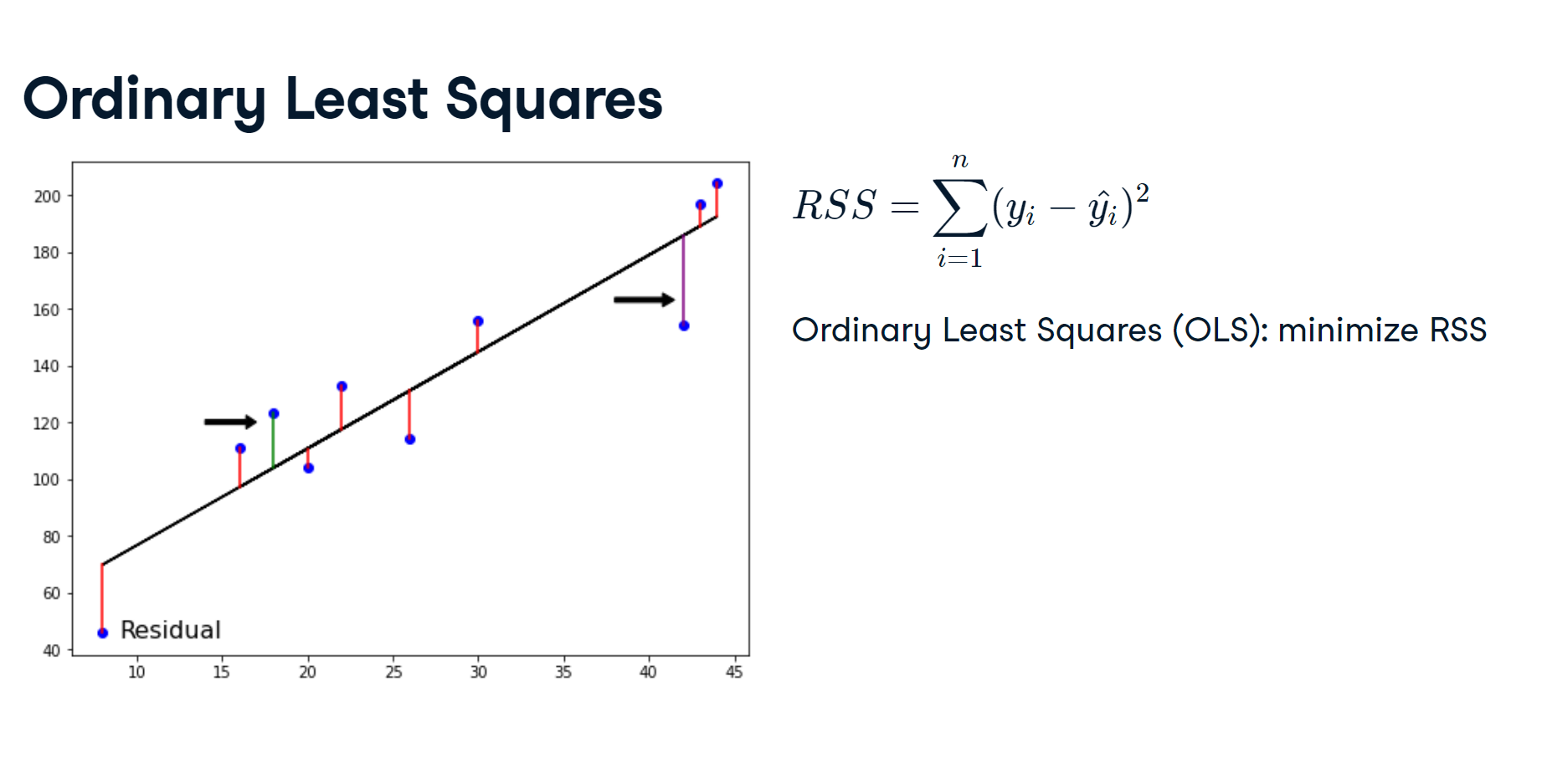

from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Create X from the radio column's values (.values to make sure they are numpy array)
features = ["tv", "radio", "social_media"]
X = sales_df[features].values
# Create y from the sales column's values
y = sales_df['sales'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
reg_all = LinearRegression()
reg_all.fit(X_train, y_train)
y_pred = reg_all.predict(X_test)
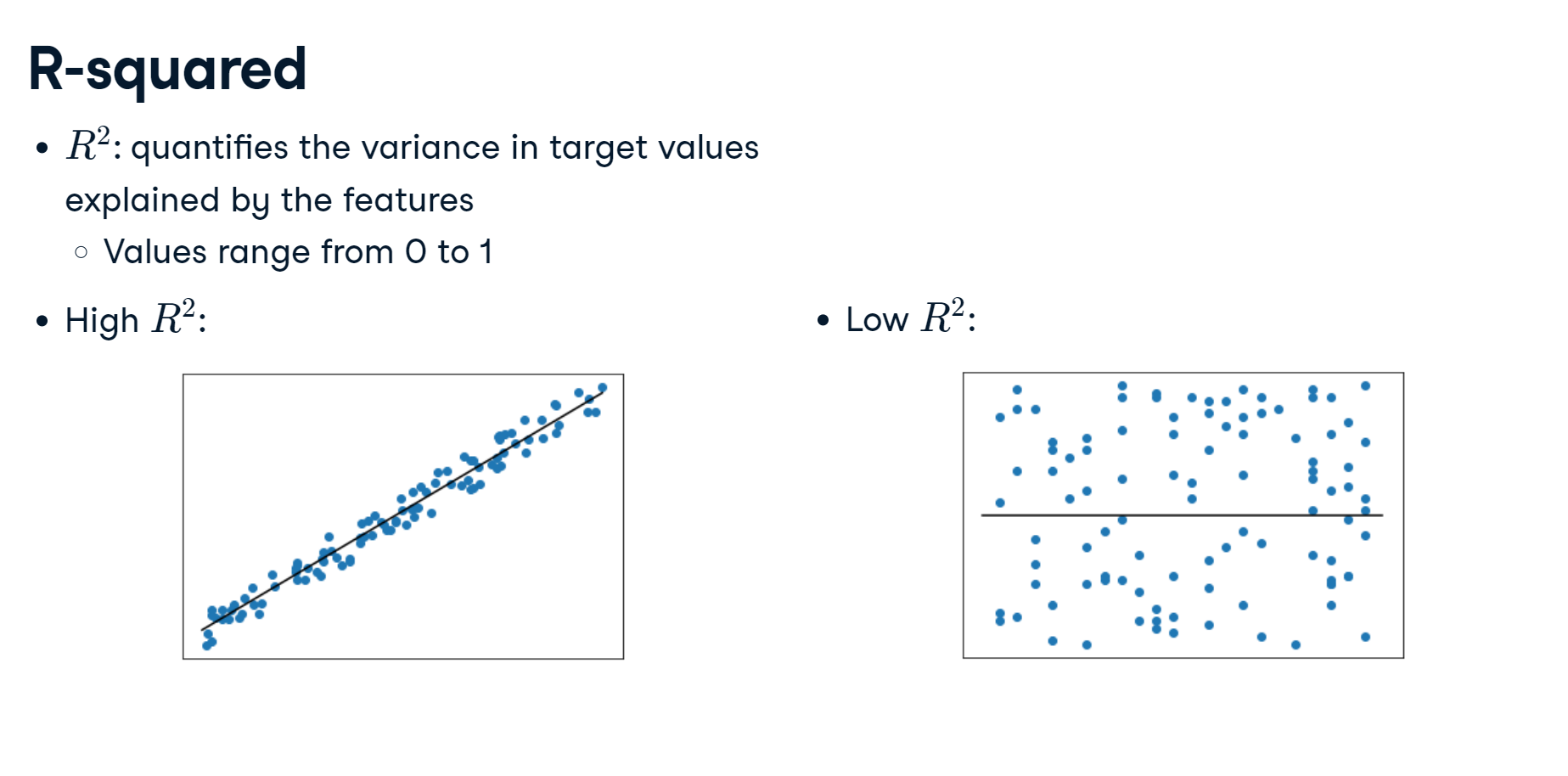
r-squared in linear regression range from 0 to 1.
R-squared values range from 0 to 1 and are commonly stated as percentages from 0% to 100%.
The R-squared may need to be above 0.95 for a regression model to be considered reliable.
reg_all.score(X_test, y_test)

from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, y_pred, squared=False)
Fit and predict for regression
Now you have seen how linear regression works, your task is to create a multiple linear regression model using all of the features in the sales_df dataset, which has been preloaded for you. As a reminder, here are the first two rows:
| tv | radio | social_media | sales | |
|---|---|---|---|---|
| 1 | 13000.0 | 9237.76 | 2409.57 | 46677.90 |
| 2 | 41000.0 | 15886.45 | 2913.41 | 150177.83 |
You will then use this model to predict sales based on the values of the test features.
LinearRegression and train_test_split have been preloaded for you from their respective modules.
Instructions:
- Create X, an array containing values of all features in sales_df, and y, containing all values from the "sales" column.
- Instantiate a linear regression model.
- Fit the model to the training data.
- Create y_pred, making predictions for sales using the test features.
X = sales_df.drop(["sales","influencer"], axis=1).values
y = sales_df["sales"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Instantiate the model
reg = LinearRegression()
# Fit the model to the data
reg.fit(X_train, y_train)
# Make predictions
y_pred = reg.predict(X_test)
print("Predictions: {}, Actual Values: {}".format(y_pred[:2], y_test[:2]))
The first two predictions appear to be within around 5% of the actual values from the test set!
Regression performance
Now you have fit a model, reg, using all features from sales_df, and made predictions of sales values, you can evaluate performance using some common regression metrics.
The variables X_train, X_test, y_train, y_test, y_pred, along with the fitted model, reg, all from the last exercise, have been preloaded for you.
Your task is to find out how well the features can explain the variance in the target values, along with assessing the model's ability to make predictions on unseen data.
Instructions:
- Import mean_squared_error.
- Calculate the model's R-squared score by passing the test feature values and the test target values to an appropriate method.
- Calculate the model's root mean squared error using y_test and y_pred.
- Print r_squared and rmse.
from sklearn.metrics import mean_squared_error
# Compute R-squared
r_squared = reg.score(X_test, y_test)
# Compute RMSE
rmse = mean_squared_error(y_test, y_pred, squared=False)
# Print the metrics
print("R^2: {}".format(r_squared))
print("RMSE: {}".format(rmse))
Wow, the features explain 99.9% of the variance in sales values! Looks like this company's advertising strategy is working well!
Cross-validation
Cross-validation motivation:
- Model performance is dependent on the way we split up the data
- Not representative of the model's ability to generalize to unseen data
Solution:Cross-validation!

Cross-validation and model performance:
- 5 folds = 5-fold CV
- 10 folds = 10-fold CV
- k folds = k-fold CV
- More folds = More computationally expensive
X = sales_df.drop(["tv","sales","influencer"], axis=1).values
y = sales_df["sales"].values
print(X.shape)
from sklearn.model_selection import cross_val_score, KFold
kf = KFold(n_splits=6, shuffle=True, random_state=42)
reg = LinearRegression()
cv_results = cross_val_score(reg, X, y, cv=kf)
# Evaluating cross-validation peformance
print(cv_results)
# [0.70262578, 0.7659624, 0.75188205, 0.76914482, 0.72551151, 0.73608277]
print(np.mean(cv_results), np.std(cv_results))
# 0.7418682216666667 0.023330243960652888
print(np.quantile(cv_results, [0.025, 0.975]))
the results are an array (each fold's result). The result is R-squared as it is the default metric for linear regression.
Cross-validation for R-squared
Cross-validation is a vital approach to evaluating a model. It maximizes the amount of data that is available to the model, as the model is not only trained but also tested on all of the available data.
In this exercise, you will build a linear regression model, then use 6-fold cross-validation to assess its accuracy for predicting sales using social media advertising expenditure. You will display the individual score for each of the six-folds.
The sales_df dataset has been split into y for the target variable, and X for the features, and preloaded for you. LinearRegression has been imported from sklearn.linear_model.
Instructions:
- Import KFold and cross_val_score.
- Create kf by calling KFold(), setting the number of splits to six, shuffle to True, and setting a seed of 5.
- Perform cross-validation using reg on X and y, passing kf to cv.
- Print the cv_scores.
from sklearn.model_selection import cross_val_score, KFold
# Create a KFold object
kf = KFold(n_splits=6, shuffle=True, random_state=5)
reg = LinearRegression()
# Compute 6-fold cross-validation scores
cv_scores = cross_val_score(reg, X, y, cv=kf)
# Print scores
print(sorted(cv_scores))
Notice how R-squared for each fold ranged between 0.74 and 0.77? By using cross-validation, we can see how performance varies depending on how the data is split!
Analyzing cross-validation metrics
Now you have performed cross-validation, it's time to analyze the results.
You will display the mean, standard deviation, and 95% confidence interval for cv_results, which has been preloaded for you from the previous exercise.
numpy has been imported for you as np.
Instructions:
- Calculate and print the mean of the results.
- Calculate and print the standard deviation of cv_results.
- Display the 95% confidence interval for your results using np.quantile().
print(np.mean(cv_results))
# Print the standard deviation
print(np.std(cv_results))
# Print the 95% confidence interval
print(np.quantile(cv_results, [0.025, 0.975]))
An average score of 0.75 with a low standard deviation is pretty good for a model out of the box! Now let's learn how to apply regularization to our regression models.
Regularized regression
Why regularize?
- Recall: Linear regression minimizes a loss function
- It chooses a coefficient, a, for each feature variable, plus b
- Large coefficient can lead to overfitting
- Regularization: Penalize large coefficients
Ridge regression
$$ Loss \: function = OLS \: loss \: function + α ∗ \sum\nolimits_{i = 1}^{n}{a_i^2} $$Ridge penalizes large positive or negative coe)cients α: parameter we need to choose Picking α is similar to picking k in KNN Hyperparameter: variable used to optimize model parameters α controls model complexity
- α = 0 = OLS (Can lead to overfitting)
- Very high α: Can lead to underfitting
X = diabetes_df.drop("glucose", axis=1).values
y = diabetes_df["glucose"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
from sklearn.linear_model import Ridge
scores = []
for alpha in [0.1, 1.0, 10.0, 100.0, 1000.0, 10000]:
ridge = Ridge(alpha=alpha)
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)
scores.append(ridge.score(X_test, y_test))
print(scores)
Performance get worse as alpha increases.
from sklearn.linear_model import Lasso
scores = []
for alpha in [0.01, 1.0, 10.0, 20.0, 50.0]:
lasso = Lasso(alpha=alpha)
lasso.fit(X_train, y_train)
lasso_pred = lasso.predict(X_test)
scores.append(lasso.score(X_test, y_test))
print(scores)
USE Lasso regression for feature selection:
- Lasso can select important features of a dataset
- Shrinks the coe)cients of less important features to zero
- Features not shrunk to zero are selected by lasso
from sklearn.linear_model import Lasso
X = diabetes_df.drop("glucose", axis=1).values
y = diabetes_df["glucose"].values
names = diabetes_df.drop("glucose", axis=1).columns
lasso = Lasso(alpha=0.1)
lasso_coef = lasso.fit(X, y).coef_
plt.bar(names, lasso_coef)
plt.xticks(rotation=45)
plt.show()

Exercise: Regularized regression: Ridge
Ridge regression performs regularization by computing the squared values of the model parameters multiplied by alpha and adding them to the loss function.
In this exercise, you will fit ridge regression models over a range of different alpha values, and print their scores. You will use all of the features in the sales_df dataset to predict "sales". The data has been split into X_train, X_test, y_train, y_test for you.
A variable called alphas has been provided as a list containing different alpha values, which you will loop through to generate scores.
Instructions:
- Import Ridge.
- Instantiate Ridge, setting alpha equal to alpha.
- Fit the model to the training data.
- Calculate the score for each iteration of ridge.
X = sales_df.drop(["sales","influencer"], axis=1).values
y = sales_df["sales"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
print(X_train.shape)
from sklearn.linear_model import Ridge
alphas = [0.1, 1.0, 10.0, 100.0, 1000.0, 10000.0]
ridge_scores = []
for alpha in alphas:
# Create a Ridge regression model
ridge = Ridge(alpha = alpha)
# Fit the data
ridge.fit(X_train, y_train)
# Obtain R-squared
score = ridge.score(X_test, y_test)
ridge_scores.append(score)
print(ridge_scores)
The scores don't appear to change much as alpha increases, which is indicative of how well the features explain the variance in the target—even by heavily penalizing large coefficients, underfitting does not occur!
sales_columns = ['tv', 'radio', 'social_media']
# Import Lasso
from sklearn.linear_model import Lasso
# Instantiate a lasso regression model
lasso = Lasso(alpha=0.3)
# Fit the model to the data
lasso.fit(X, y)
# Compute and print the coefficients
lasso_coef = lasso.coef_
print(lasso_coef)
plt.bar(sales_columns, lasso_coef)
plt.xticks(rotation=45)
plt.show()

See how the figure makes it clear that expenditure on TV advertising is the most important feature in the dataset to predict sales values! In the next chapter, we will learn how to further assess and improve our model's performance!